How we built a globally distributed mesh network to scale WebRTC

Any time you’ve used Zoom, Discord, or Twitter Spaces, you’ve interacted with a media server. A media server is responsible for allowing clients to do things like exchange camera or microphone data in real-time. It behaves quite differently from say, an HTTP server. A media server hosts sessions, which are stateful container objects. When clients (i.e. participants) wish to exchange media, they connect to a media server and join the same session. Media packets then flow from source to server, that—akin to a router—forwards them to one or more destinations in a matter of milliseconds.
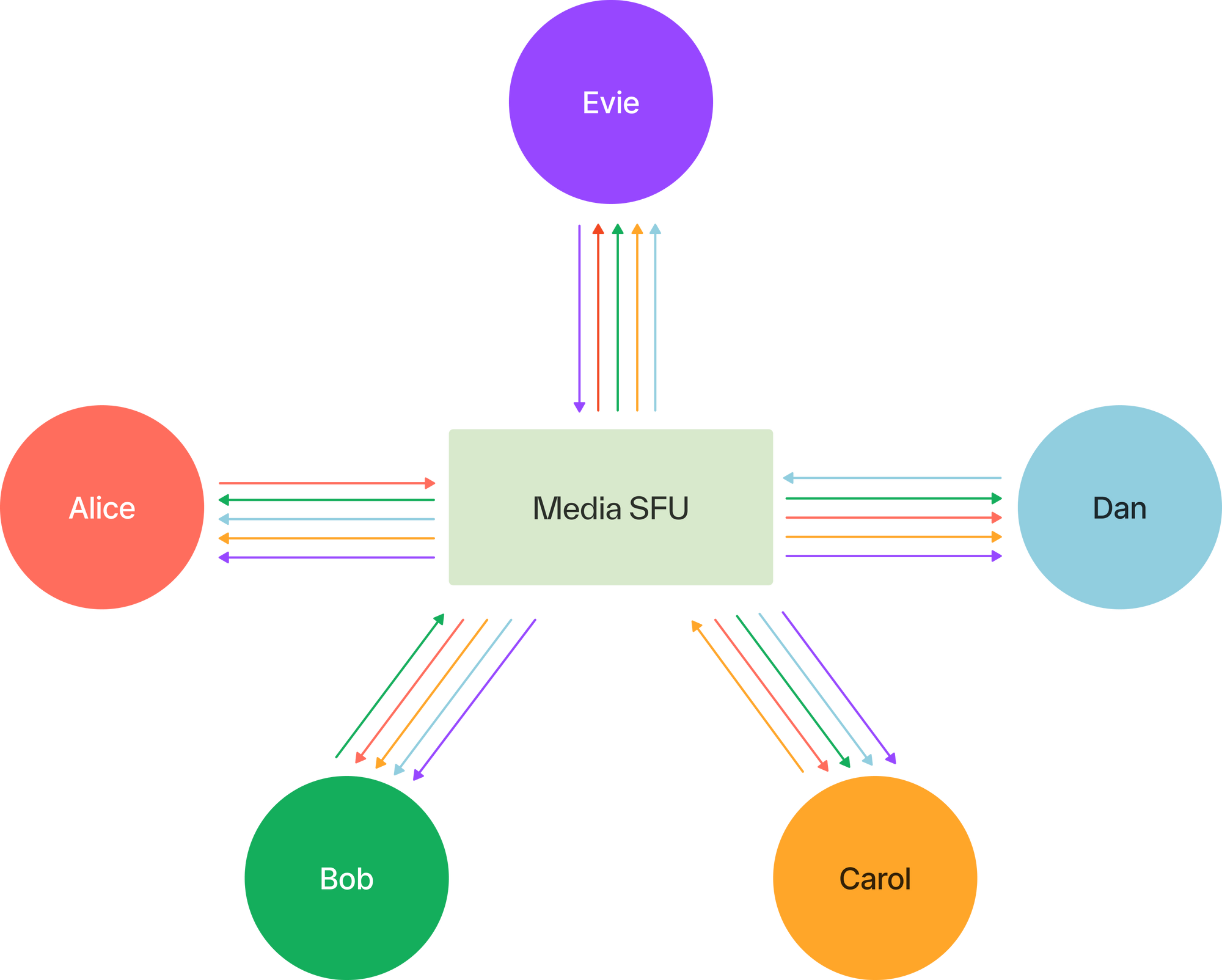
The increased use of real-time video and audio in our lives has brought a need to deploy and scale media infrastructure. Typically, media servers are set up in a single-home architecture. Many server instances are deployed in data centers around the world with traffic load-balanced between them, but a particular session can only be hosted by one instance. That means, participants interested in exchanging media with one another must connect to the same media server, regardless of where the participants are located. While this architecture is fairly easy to set up and operate, it has significant drawbacks:
Single point of failure
A single-home architecture may be the most efficient way to distribute media, but what happens when the server has a hardware failure (and trust me, it will)? From a technical standpoint, all in-memory state is lost and media stream (i.e. track) forwarding, stops. From a product perspective, any pause or significant disruption to track forwarding leads to a jarring user experience.
Limited scale
The number of tracks simultaneously exchanged during a session is limited by a server’s resources. Forwarding WebRTC media is a non-trivial operation; video consumes significant bandwidth, and all data must be encrypted prior to transmission.
To give you an idea of the amount of data a server has to process, consider a session with 50 participants, where each one is receiving video tracks from all 49 others. Assuming a moderate video quality of 360p @ 500kbps, the server’s outbound bitrate would be:
50 participants * (500kbps * 49 streams) = 1.23 GbpsAt over 1 Gbps of outbound bandwidth, we’re approaching the sustainable I/O limit of most network links — and that’s without considering CPU utilization. Quite clearly, a single-home architecture can only handle smaller real-time sessions.
Increased latency
Real-time video and audio isn’t just being used more, it’s being used more widely. Participants are often located on opposite sides of the world. With a centralized server approach, it’s likely some will be sending and receiving tracks from far away. With a perfect network, this scenario poses little issue, but real-world networks are messy and packets are sometimes lost in transmission.
Like other real-time protocols, WebRTC uses UDP instead of TCP because it doesn’t suffer from head-of-line blocking. When a packet is lost, a receiver notifies the sender by sending back a NACK (negative acknowledgement) message. Upon receiving a NACK, the sender would retransmit the lost packet from its buffer. This process is known as stream repair, and without it, playback halts.

The problem is, in practice, most packet loss occurs between the receiver and their ISP. If the media server is far away from a participant, the NACK-to-retransmission sequence will take longer to resolve. If a track isn’t repaired quickly enough, the user experience will be impacted.
Building a mesh network for media-forwarding
We started working on LiveKit Cloud with some ambitious design goals:
- Compatibility: Works with LiveKit’s protocol and client SDKs
- Reliability: No SPOFs and entire data center failures must be survivable
- Quality: A media server within 100ms of anyone in the world
- Scale: Supports millions of real-time participants per session
To accomplish the above required a different approach, one that combined both, our expertise in media and in distributed systems.
Maintaining compatibility with LiveKit’s Open Source stack (OSS) was important to us. We didn’t want any developer locked into using Cloud, or needing to integrate a different set of features, APIs or SDKs for their application to work with it. A developer should be able to switch between Cloud or self-hosted without changing a line of code.
This implied, at a minimum, our Cloud media server needed to support the same open-source signaling protocol. One option was to privately fork LiveKit’s SFU, but we decided to adopt it wholesale as fixes and improvements benefitted both OSS and Cloud.
From single-home to multi-home
Like most media servers, LiveKit’s SFU was designed around a single-home architecture. A simplified view of our session looks like this:
type Session struct {
participants []Participant
}
// forwards media to other participants via WebRTC connection
func (s *Session) onPacketReceived(packet Packet, trackID string, from Participant) {
for _, p := range s.participants {
if from != p {
p.GetDownTrack(trackID).WriteRTP(packet)
}
}
}
// sends metadata updates via signal connection
func (s *Session) onParticipantChanged(p Participant) {
metadataUpdate := p.Metadata()
for _, p := range s.participants {
if from != p {
p.SendUpdate(metadataUpdate)
}
}
}This wouldn't suffice to meet our design goals. In a multi-home architecture, a session is no longer a physical construct—mapping to a single machine running in a data center—but a logical construct: a session can span multiple servers across potentially multiple data centers. With this approach, each participant would minimize their latency to the SFU by connecting to the nearest server.
If participants are connected to different servers but belong to the same session, how do we allow them to share presence? The first step was to separate a participant's metadata from their media transport. A participant's metadata includes their identifier, connection state, and the list of tracks they've published.
type Participant interface {
Metadata() *ParticipantInfo
}
type LocalParticipant interface {
Participant // inherits from Participant
GetDownTrack(trackID string)
SendUpdate(info *ParticipantInfo)
}We moved all transport-specific functionality to a LocalParticipant, and we modified our Session accordingly:
type Session struct {
localParticipants []LocalParticipant
remoteParticipants []Participant
}Each server involved in hosting a particular session holds presence information for every participant in that session. At 100 bytes per participant, it's small enough to scale to millions of them. Participants connected to a specific instance are stored in the localParticipants slice of that instance's copy of the session. Congruently, remoteParticipants holds the participants in the session connected to other instances. Each instance forwards media and metadata for only their local participants.
Synchronizing state
We must now ensure every instance hosting the session has a consistent view of the shared state. From the perspective of a particular instance A, when a new participant joins the session from server B:
- A's local participants receive the new participant's metadata
- the new participant connected to B receives presence information for all existing participants
Synchronizing shared data across multiple servers is a key challenge in distributed systems. CAP theorem states that between consistency, availability, and partition tolerance only two are guaranteed. In our system, availability and partition tolerance are non-negotiable, but we can tolerate eventual consistency – it's perfectly acceptable if a participant appears in a session slightly later to others.
In distributed systems, having an authority for a piece of data simplifies synchronization challenges; we can trust the authority instead of having to resolve write conflicts. Fortunately, there's a natural authority for a participant's state: the server they're currently connected to. With only the authority performing writes to a that state, other servers simply wait to receive read-only copies of the data.
Message bus over database
In most cases, a database is the logical choice for data synchronization tasks. At first, we evaluated various databases to see if they could meet our requirements.
Traditional ones like Postgres pose a single point of failure. While replication and standby instances help mitigate some of that, we'd still be bottlenecked fulfilling queries as we scaled up query volume. In addition, we need access to the shared state across multiple data centers and synchronizing multiple databases remains an unsolved challenge.
We also evaluated distributed databases like Google Spanner and Cockroach DB. They were designed to work across multiple data centers, but we found they were both optimized for consistency instead of AP (availability and partition-tolerance). This would mean writes could be blocked if connections between regions are disrupted.
It turns out, we didn't need the persistence guarantees of a database. Participant state in a real-time system is transient – only relevant when a participant is connected to a server. And since just a single server is making changes to a record at any given time, we didn't require the sophisticated locking mechanisms a database provides.
What we needed was a message bus that can quickly and reliably distribute changes to the participant state.
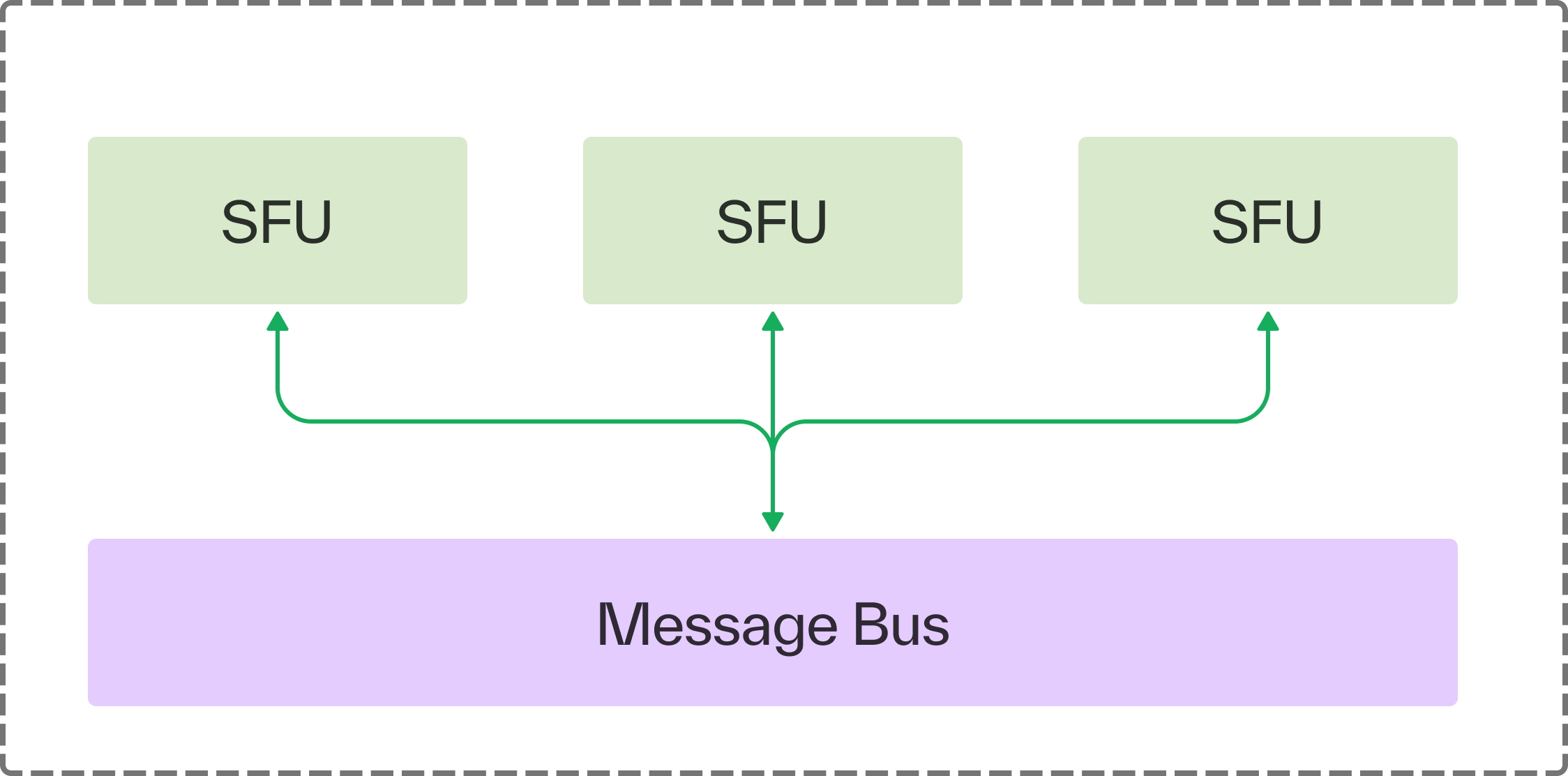
Our SFUs would exchange this state using a pub-sub protocol. Any time there's a state update, the authority publishes it to a session-specific topic where other servers co-hosting that session are also subscribed to that topic. All servers must receive state update messages at least once, ensuring eventual consistency.
What happens when a participant joins a server that wasn't previously hosting the session? There isn't a database to retrieve past updates.
This too can be fulfilled by our message bus. A server without a copy of the current state sends a message on the bus requesting a state re-sync. Recipients of that message simply republish the state of their local participants to the bus.
Relaying media
To cascade across SFUs, we needed a protocol to relay media between them. While the natural choice was WebRTC, given that our SFUs already use it to transmit data to clients, we decided against it for a few reasons:
- WebRTC uses ICE for transport, a protocol designed to traverse firewalls. It added unnecessary complexity and latency to server-to-server communications.
- WebRTC used SDP as the control protocol. No one should be using SDPs if they can help it.
- Forwarding simulcasted tracks would have required additional coordination between the sender and receiver.
In the end, we decided to use a custom FlatBuffers-based protocol, but like WebRTC, we still use RTP for media packets. A custom protocol allows us to supplement packets with additional metadata, like track identifiers. It also let us uniformly deal with packet loss between sender and receiver. In WebRTC, video, audio, and data channels have different ways of handling packet loss.
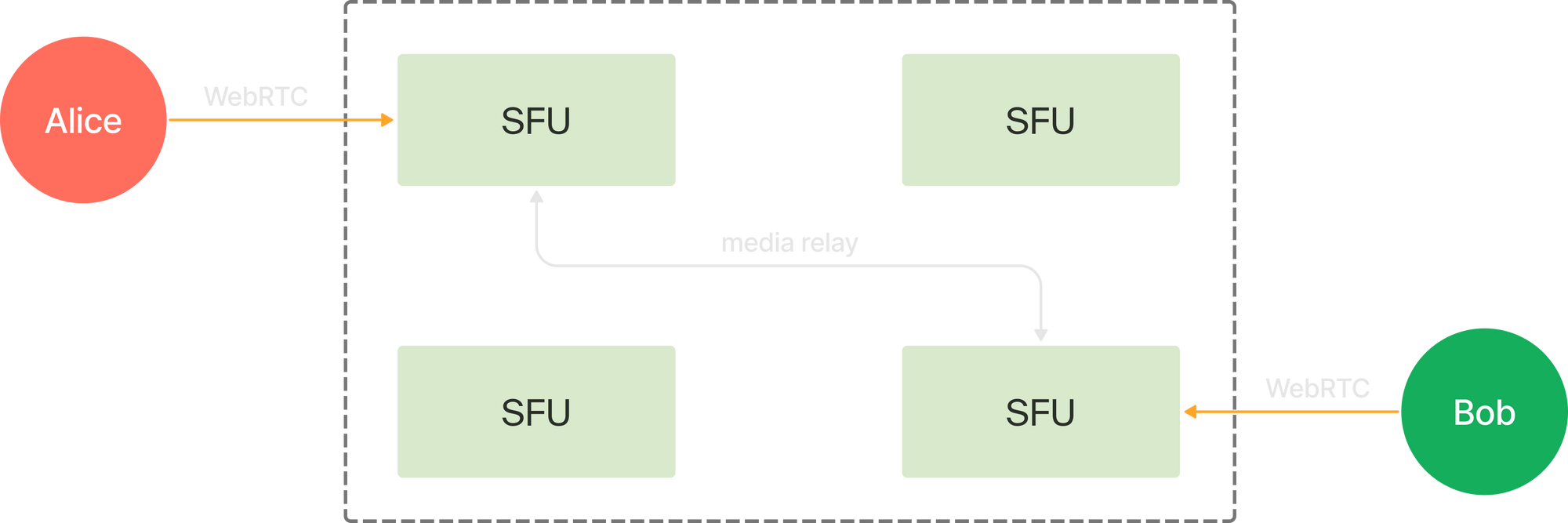
In LiveKit SFU, we've added abstractions to treat a relay destination like just another participant. Our send loop became something like this:
func (r Receiver) forwardRTP(packet Packet) {
for _, dt := range s.downtracks {
p.WriteRTP(packet)
}
}On the receiver side, each media server determines which tracks it needs based on the subscriptions of its local participants. It then performs discovery to see which servers are able to fulfill a relay request. Servers with data for the track respond to that request, along with their capacity and routing information.
Each receiving media server makes an independent decision regarding which server to fetch tracks from. The decision weighs several factors, including balancing load and the path distance to the origin of a track. Having each instance acting independently, rather than relying on a central coordinator, is crucial for fault tolerance.
With this approach, server instances automatically reconfigure the shape of the mesh for individual tracks. In a livestream, when an audience of 20,000 people attempt to stream from a single publisher, relays will organize into layers for that track, preferring shorter paths when available.
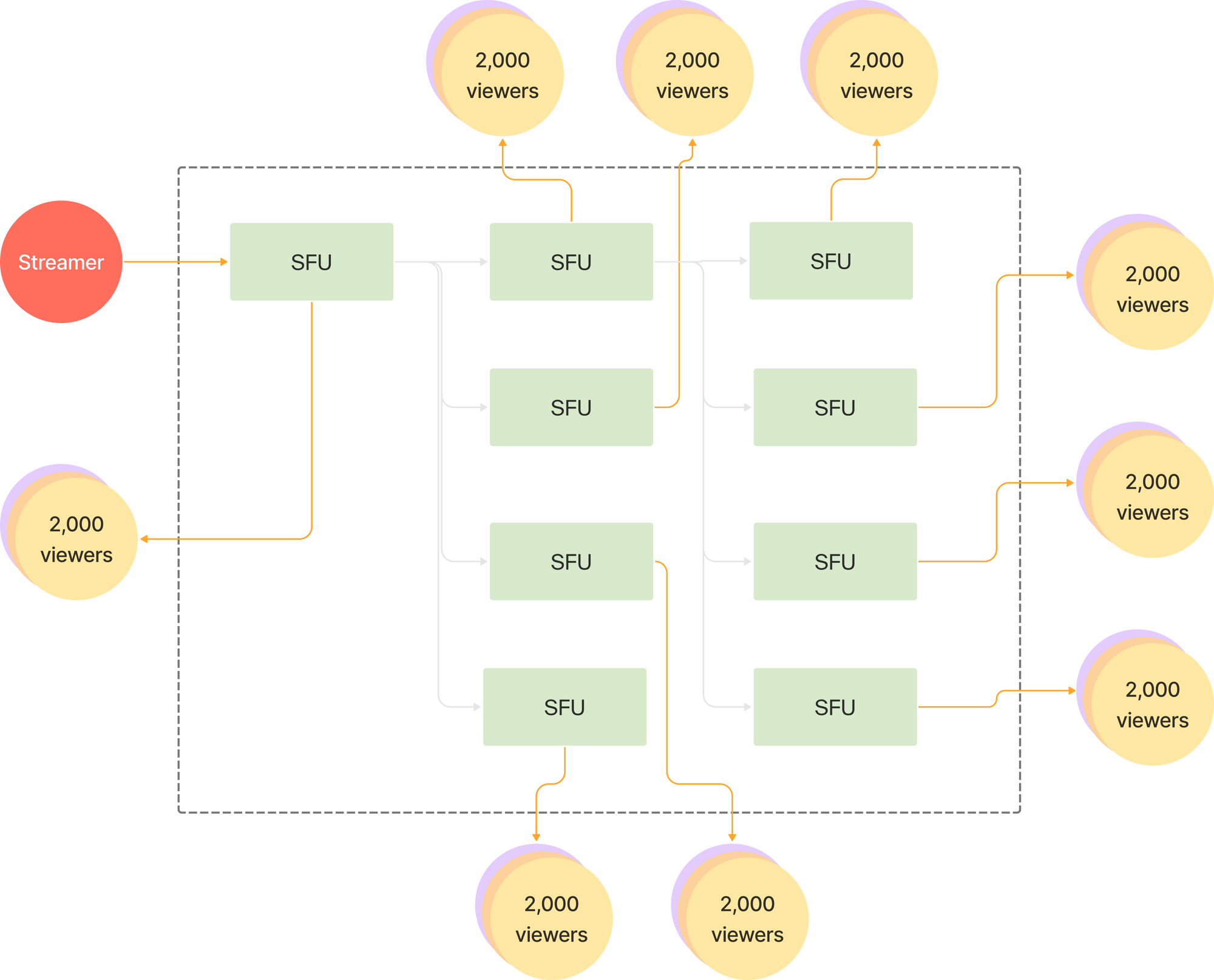
By contrast, for a large conference call the same set of servers form a full mesh, retrieving media from one another as needed.
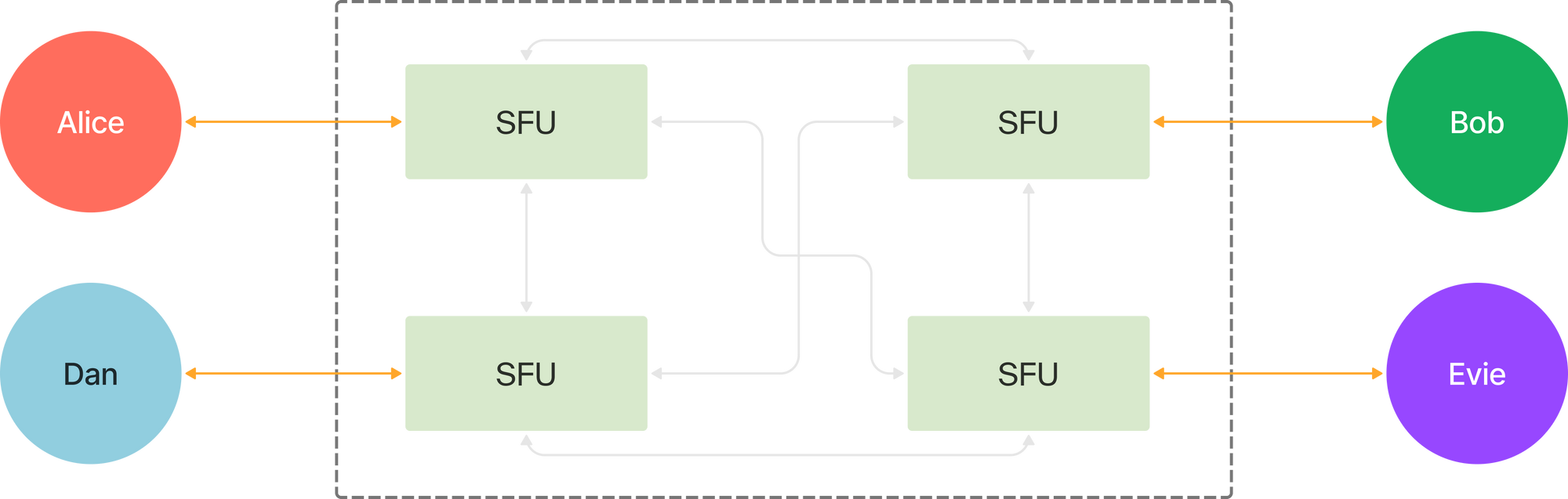
Going global
Running global infrastructure meant we'd need multiple points of presence (PoP) distributed around the world. Each one delivering media to end-users with less than 100ms of latency. This brought a few additional challenges:
Linking data centers
LiveKit Cloud was designed around a multi-cloud topology: we run our infrastructure across a blend of cloud providers. Thus, we needed a way for servers to securely communicate with one another across data centers and clouds. While some cloud providers have proprietary solutions to create peering connections between VPCs, they don't work cross-cloud.
After evaluating multiple options, we chose an overlay network: a software-based virtual network which runs atop a physical one. Data traveling across this network is encrypted and every server instance, regardless of data center or cloud is addressable by any other instance.
Fault tolerance
After spending most of our careers running services at scale, we've come to embrace Murphy's Law: anything that can fail, will. Resiliency is a fundamental part of any sound distributed system design. In the last nine months operating LiveKit Cloud, we've seen all kinds of failures: hardware malfunctions, power outages, severed fiber links, even entire data centers going offline.
To deliver 99.99+% availability, there must be layers of fault tolerance built into every component.
In a multi-home architecture, failures of a single media server can be recovered by moving impacted participants to another instance. All LiveKit clients have built-in retries to handle scenarios like this.
We also had to architect our shared infrastructure, like the message bus, to be isolated to individual data centers. With the exception of relaying media tracks, a server does not rely on shared resources located outside of its data center. The result of this design is if an entire data center fails, participants can still be routed to a nearby PoP.
Transparent failover with live migrations
Even though we can mitigate media server failures by routing to a different server, the user experience can still be jarring. When a disruption occurs, a participant's client would typically tear down that connection and re-establish both the signal and PeerConnection. All of the participant's local state, including tracks they're receiving, need to be reset too. By the time the entire reconnection sequence completes, which could take up to five seconds, the participant's application UI may have changed substantially.
Many engineers on the LiveKit team have worked on popular consumer products, and strongly empathize with end-users. The experience described above just wasn't good enough, so we created a way for migrations to be processed on the server without any change to client state. We call it live migrations. It leverages a feature in WebRTC called an ICE restart. An ICE restarts allows a network connection to seamlessly use a different path without interruption (e.g. switching from WiFi to cellular).
Live migrations perform an ICE restart on the client side, but point to a different server. The new server examines the state the participant is expected to be in, and reconstructs its local (server) state to mirror that participant's client state, including any tracks they're already subscribed to. To the participant, it would appear like their connection was restored via the ICE restart process.
Demo of seamlessly migrating to a new server
With live migrations, the disruption caused by a server-side failure is reduced to under a second! It also gives us the ability to proactively identify issues and migrate participants to healthy servers before any disruption takes place.
Putting it all together
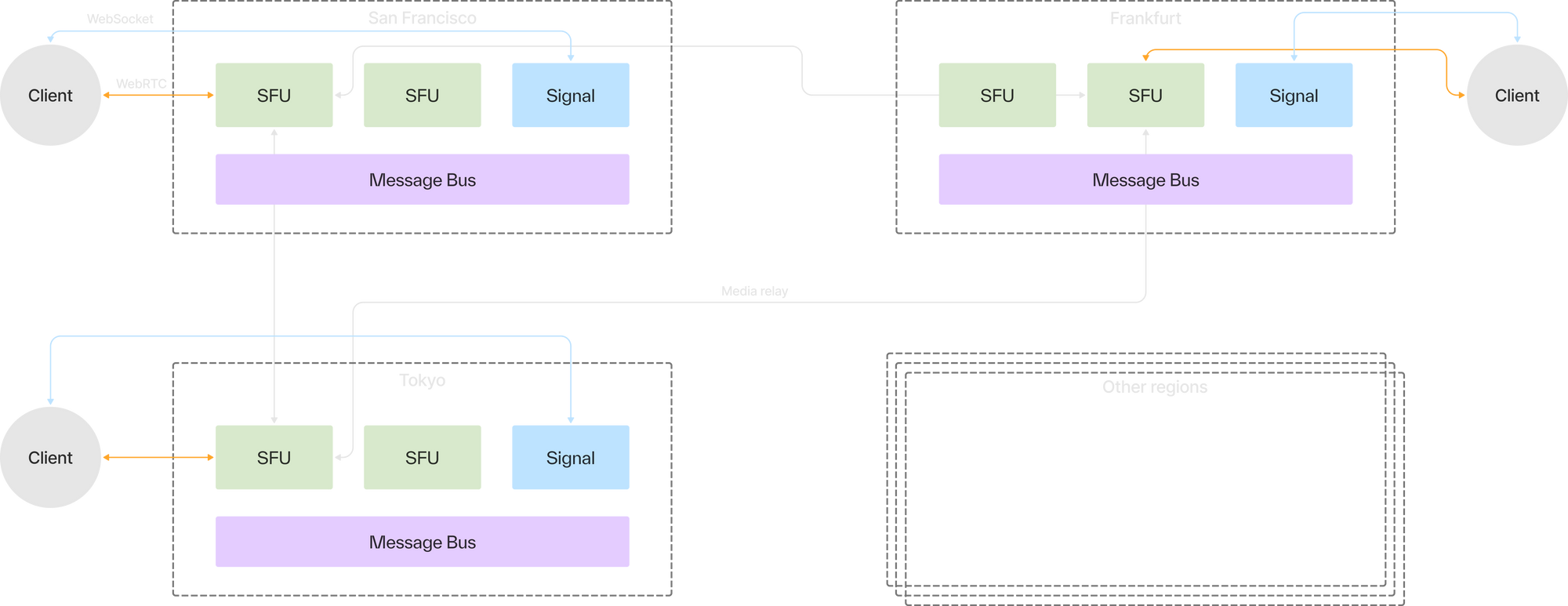
When we put the aforementioned pieces together, our final architecture looks like the diagram above. Each data center is self-contained, sharing no infrastructure with other data centers. Despite that, data centers may still co-host the same session via point-to-point mesh links. Any given session is resilient to node, data center and even entire cloud failures. This architecture allows us to scale to hundreds of thousands of participants in a single real-time WebRTC session. We think this stack will usher in the next generation of real-time applications and can't wait to see what you build with it.
If you want to give it a try for free, head on over here. And if you're interested in working on challenges like this, come work with us!