Using a transformer to improve end of turn detection

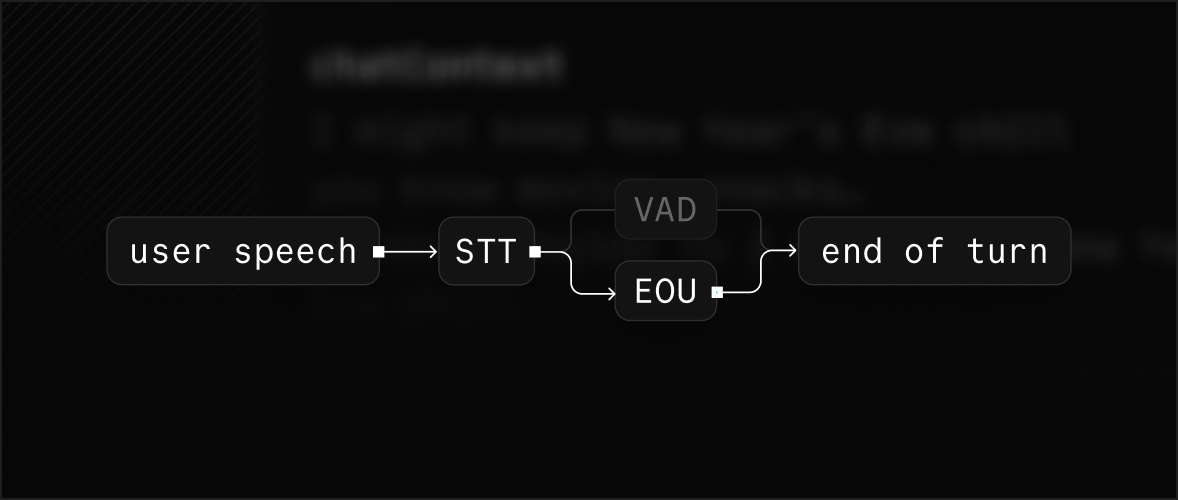
One of the hardest problems to solve right now for voice AI applications is end-of-turn detection. In the context of conversational AI, turn detection is the task of determining when a user is done speaking and when an AI model can respond without unintentionally interrupting the user.
Currently, the most common technique for detecting the end of a turn is called phrase endpointing. A phrase endpointer is an algorithm that tries to figure out when a user has finished speaking a complete thought or utterance. Pretty much everyone, including LiveKit’s Agents framework, uses voice activity detection (VAD) as a phrase endpointer. It works like this:
- Run audio packets through a neural net, which outputs whether the audio contains human speech or not.
- If the audio sample contains human speech, the user is not done speaking.
- If the audio sample does not contain human speech, start a timer to track the length of “silence” (i.e. absence of detectable human speech). Once a certain threshold of time—set by you, the developer—has passed without human speech, that moment represents the end of an utterance. The AI model can now run inference on the user’s input and respond.
Agents use Silero VAD to detect voice activity and provide timing parameters to adjust its sensitivity. Once an Agent determines the user has stopped speaking, the framework introduces a delay before initiating LLM inference. This delay helps distinguish between natural pauses and the end of a user’s turn. You can configure this delay using the min_endpointing_delay parameter. The default value for min_endpointing_delay is 500ms. That means once VAD detects a transition from human speech to the absence of such, and that absence lasts for at least 500ms, an end of turn event is triggered.
You can get your agent to respond faster by lowering the endpointing delay threshold, but at the expense of frequent interruptions. If you increase the threshold to a second or two, your agent will feel unresponsive. The obvious problem here is a one-value-fits-all approach can’t possibly account for every use case, every speaking style, or every spoken language.
An even bigger issue is VAD only picks up on when someone is speaking (by analyzing the presence of an audio signal), whereas a human also uses semantics, what someone says and how they say it, to figure out when it’s their turn to speak. For example, if someone says, “I understand your point, but…” — VAD would call this an end of turn, but a human would most likely keep listening.
For a few months now, we’ve been exploring how to incorporate semantic understanding into LiveKit Agents’ turn detection system. After a lot of experimentation and testing, we’re excited to release an open source transformer model that uses the content of speech to predict when a user has finished speaking. Before we dive into how it works and how it’s used in turn detection, check out the results:
Shayne doing a before-and-after with the new turn detection system in LiveKit Agents
How the model works
Our End of Utterance (EOU) model is a 135M parameter transformer based on SmolLM v2 from HuggingFace and fine-tuned for the task of predicting the end of a user’s speech. We chose a small model given that inference needed to run on the CPU and in real-time. EOU uses a sliding context window of the last four turns in a conversation between the user and agent.
While a user is speaking, their speech is transcribed to text using a (developer-specified) speech-to-text (STT) service and each word is appended to the model’s context window. For each final transcription received from STT, the model makes a prediction with a confidence level as to whether the trailing end of the current context represents the end of a turn for the current speaker. Right now, EOU can only make predictions against English transcriptions, but we’re planning to add support for more languages in the coming months.
The way we use the model is simple: model predictions are used to dynamically shorten or extend the VAD silence timeout. This means the agent will wait for longer periods of silence if EOU suggests the user hasn’t finished speaking. In our testing, we’ve found this strategy results in significantly less interruptions without compromising on responsiveness. In comparison to using VAD alone, EOU with VAD:
- Reduces unintentional interruptions by 85%
- Falsely indicates that the turn is not over 3% of the time
It’s been especially useful in conversational AI and customer support use cases like conducting interviews and collecting data from a user such as addresses, phone numbers, or payment information. Some more demos:
- Ordering a pizza
- Providing your address for a shipment
- Giving your account number to customer support
How to use the new model in your agent
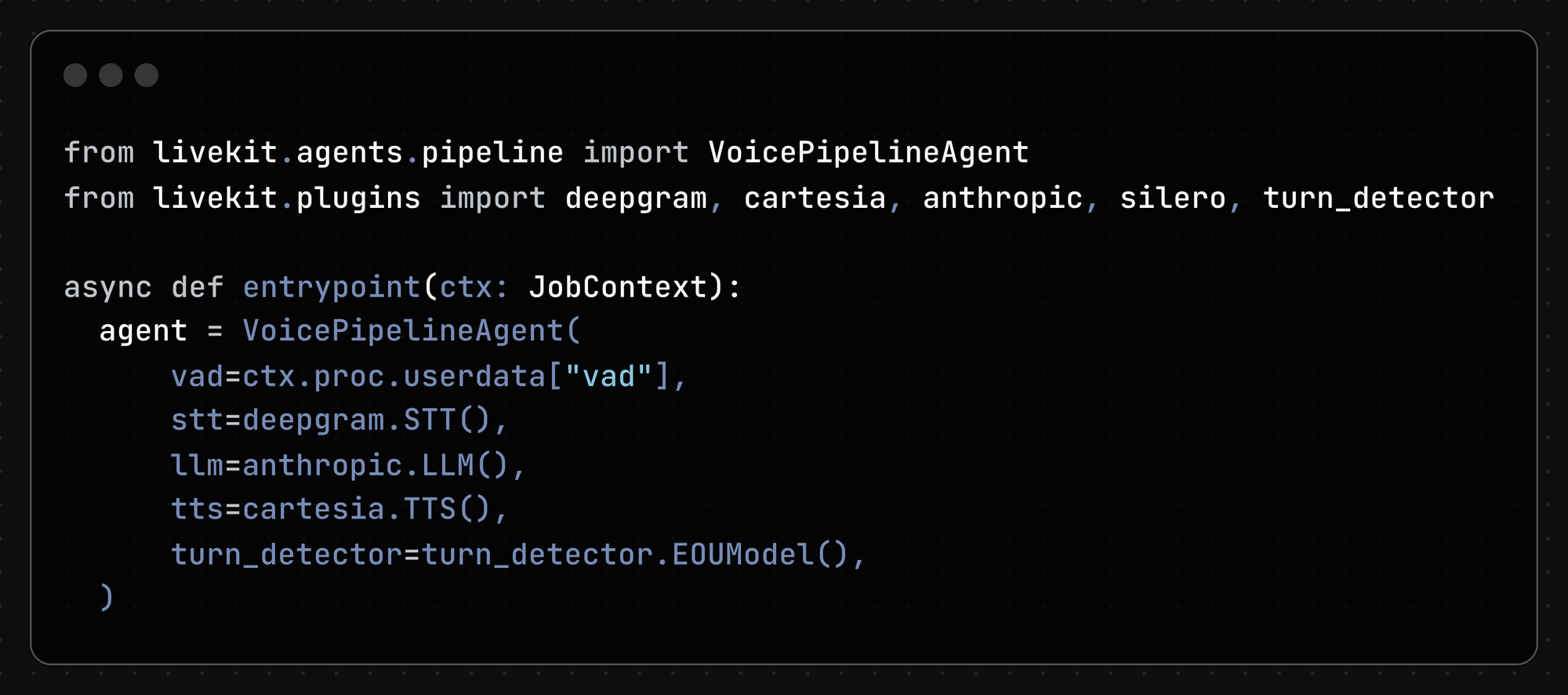
We’ve packaged up our new turn detector as a LiveKit Agents plugin, so adding it to your voice agent can be done in a single additional kwarg in the VoicePipelineAgent constructor (you can find the full example code here):
The future of turn detection
In addition to extending EOU to support additional languages, we also want to explore improvements like increasing the context window and improving the model’s inference speed (currently ~50ms). EOU is trained on text, so while it’s effective in pipeline architectures (i.e. STT ⇒ LLM ⇒ TTS), where speech is converted to text before further processing, it can’t be used with natively multimodal models that consume audio input directly, like OpenAI’s Realtime API.
For doing content-aware turn detection with multimodal models, we’re working on new audio-based model that will not only consider what a speaker says, but how the speaker expresses themselves, using implicit information within human speech like intonation and cadence.
It’s difficult to describe the exact process we humans use for knowing when it’s our turn to speak, which makes the task a good candidate for machine learning-based approaches. Even humans don’t get this right all the time, and non-verbal cues improve our performance at this task. We interrupt others less in person than on Zoom, and less on Zoom than over the phone. We believe that research in this area is crucial to building more humanlike AI that feels natural to interact with. We’re excited to make our first contribution to the community with this model and expect to see a lot of innovation in this space over time.
If you’re interested in exchanging ideas, contributing to the project, joining the core team, or building something that uses LiveKit’s new turn detection model, drop us a note in the LiveKit community.