An open source stack for real-time multimodal AI


It feels impossible to keep up with everything happening in AI. There’s seemingly a new breakthrough every week. And even though we won’t have AGI in 2024, it’s interesting to consider what the world might look like when we do.
In particular, the LiveKit team has been exploring how we’ll interact with AGI. When a computer is as smart as a human, we’ll probably communicate with it the way we do with other humans.
We use our eyes, ears, and mouths; AGI will use cameras, microphones, and speakers.
Human interaction is multimodal and real-time. Human-AGI interaction will be too.
While an LMM version of Samantha or J.A.R.V.I.S. is a ways off, the core components for building real-time multimodal AI “agents” are already here. Most LLMs take in text as input and generate text as output, but some AI models are purpose-built to transform other modalities to text, or synthesize audio/video from text in real-time.
For example, transcribing and synthesizing speech can now be done in a couple hundred milliseconds:
Unbelievable 🤯
— Linus (●ᴗ●) (@LinusEkenstam) December 8, 2023
This is Deepgram, I thought real-time AI convos where at least 6-12 months out. I was wrong.
The TTS in this demo is 100% real. AI Agents are about to become very real. pic.twitter.com/zWfEE7xSEJ
And just a few weeks ago, Fal released an API for real-time image generation:
📸 a photo booth powered by AI
— jordan singer (@jsngr) December 16, 2023
with real-time latent consistency models, here’s a new kind of camera app: pic.twitter.com/KyYRANaRVl
Similar to LLMs, these models that process or synthesize voice and video run on GPUs in a data center. But a user’s camera, microphone, screen, and speakers are on their device, located somewhere out in the world. To create a humanlike conversation with AI, we need to transport data between the server and client as quickly as possible.
One idea is to try using a WebSocket. WebSockets use TCP and are great for low data rate transmissions, but using them for streaming audio or video over the public internet is problematic. That’s because most packet loss happens between the client and ISP, and when it does, HOL blocking can increase latency or cause stutters and delays in audio/video playback.
WebRTC, on the other hand, was designed for ultra low-latency media transmission and is the only widely supported method for (indirectly) accessing a UDP socket in a web browser. Raw WebRTC though is complicated, has inherent scale limitations from it’s p2p architecture, and requires you to implement your own cross-platform signaling protocol.
LiveKit’s open source server and SDKs solve all these issues for you but there’s one more: WebRTC doesn’t natively work on the server which an AI agent needs to communicate with clients in real-time.
Introducing LiveKit Agents
Today, we’re excited to unveil a new addition to LiveKit’s open source stack: Agents.
Agents is a collection of APIs, services, and tools that make it easy to build real-time, multimodal AI applications. The framework consists of a few different pieces:
Backend SDKs
Core backend libraries in Python, Rust, and Node (in development) for building programmable LiveKit participants. Each SDK is built on top of a common Rust core and provides convenient hooks for processing incoming media streams and automatically manages tricky parts like buffering outgoing audio or video.
from livekit import rtc
import asyncio
async def main():
room = rtc.Room()
async def receive_frames(stream: rtc.VideoStream):
async for frame in stream:
# received a video frame!
pass
@room.on("track_subscribed")
def on_track_subscribed(
track: rtc.Track,
publication: rtc.RemoteTrackPublication,
participant: rtc.RemoteParticipant,
):
if track.kind == rtc.TrackKind.KIND_VIDEO:
video_stream = rtc.VideoStream(track)
asyncio.create_task(receive_frames(video_stream))
await room.connect(URL, TOKEN)Connect to a LiveKit session and process frames from published video tracks
Plugins
To build KITT we originally glued together VAD, Google’s speech-to-text (STT) and text-to-speech (TTS), and GPT-3.5 Turbo for inference. A lot of time went into stringing together APIs and optimizing the pipeline end-to-end, for low latency.
In the framework, we’ve included a set of prebuilt plugins that make it simpler to compose together agents like KITT. Agents ships with third-party integrations such as DeepGram, Whisper, ElevenLabs, Fal, and Open AI. Over time, we plan to expand the number and variety of plugins and welcome community contributions. We’ve also included helpful utilities like a VAD plugin, which detects when a user is (or isn’t) speaking, and a sentence splitter for tokenizing large paragraphs of text to stream via TTS.
import asyncio
from livekit import rtc
from livekit.plugins import deepgram
async def recognize_task(stream: deepgram.SpeechStream):
async for event in stream:
if event.is_final:
final_speech = event.alternatives[0].text
async def process_track(track: rtc.AudioTrack):
stt = deepgram.STT(model="nova-2-general")
audio_stream = rtc.AudioStream(track)
stt_stream = stt.stream()
asyncio.create_task(recognize_task(stt_stream))
async for audio_frame in audio_stream:
stt_stream.push_frame(audio_frame)Use DeepGram to process streaming speech and convert it into text
Playground
To quickly prototype and test your multimodal agents, we’ve built the Agents Playground. It’s a client application pre-wired for streaming voice, video or text to your agent and receiving streams back. It also includes the ability to switch input devices and dial into sessions via phone. We have a lot of exciting features planned for the Playground, so stay tuned!
Orchestration
Once you’ve built and tested your agent and the client interface to interact with it, the next step is going to production. Deploying and scaling an agent is different from the typical website though. An agent performs stateful work, and has to retain that state for the entire duration of a conversation. The length of these conversations can vary greatly; some may last seconds while others go on for hours. If you used a traditional HTTP load balancer, the variance in session length would lead to uneven load across your web servers. Restarting a live agent when deploying a new version is also tricky, since you don’t want to interrupt an active conversation between an agent and user.
Agents are similar to background workers in that they process jobs (i.e. conversations) from a shared queue. The difference, however, is an agent is a foreground worker. A conversation with one is an online, synchronous job, with potentially many turnovers containing dynamic sequences of inputs and outputs.
It turns out we’d already built an orchestration system for long-running foreground jobs at LiveKit: the one used for Cloud Egress. This system now manages thousands of concurrent recording and multistreaming workloads. We learned that when scaling these types of jobs, it’s important to not over-utilize the underlying machine instances. Any delays in processing may lead to choppy audio or video, in a recording or in the case of agents, being streamed directly to a user.
Borrowing ideas from our Cloud Egress orchestrator, we built a new, (open source) general purpose system that makes going to production with your multimodal agents a turnkey process.
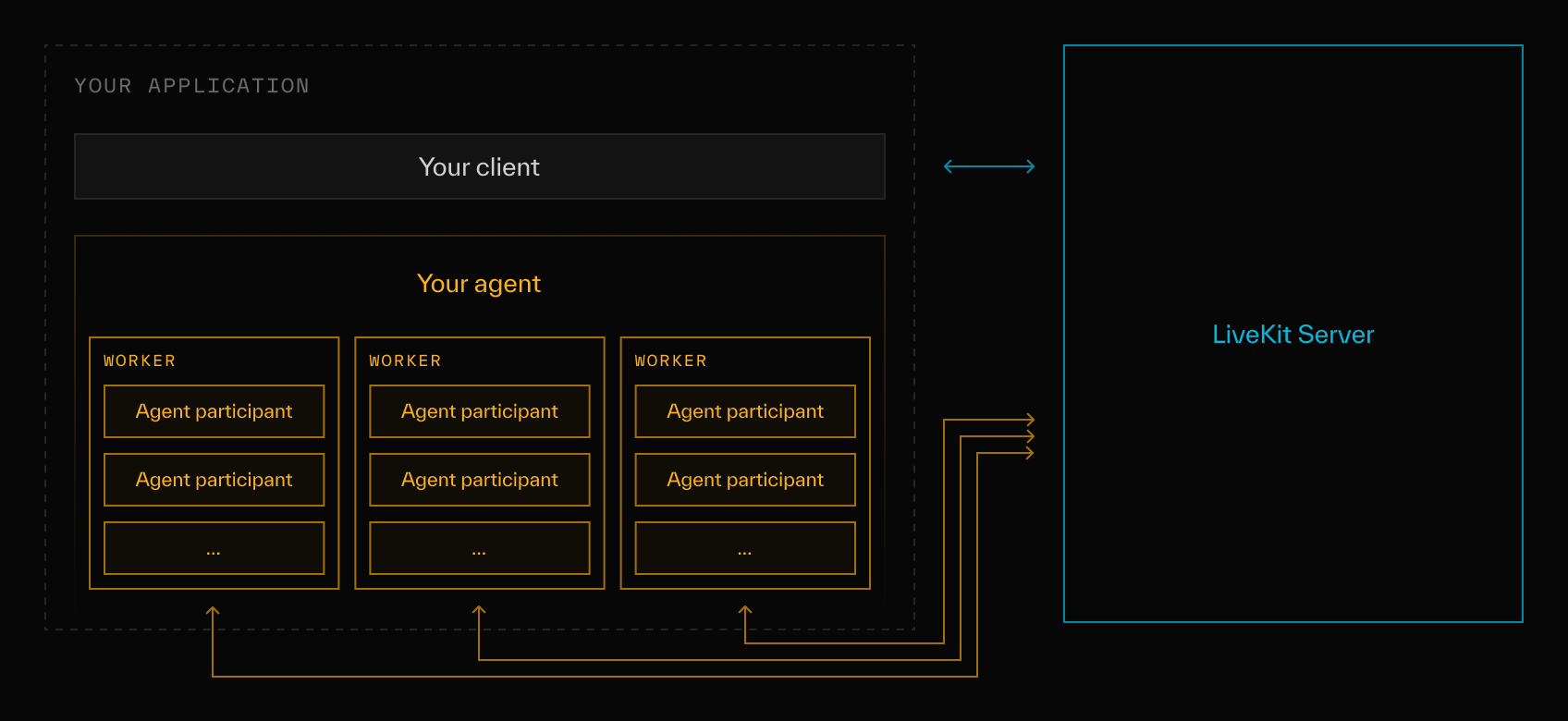
When your program registers with a LiveKit server instance, we let it know when a new "job" comes in (i.e. a new room is created). If your program accepts this job, an instance of your agent is created and joins the room. The Agents framework automatically monitors agent connectivity and load balances across your pool of agents.
from livekit import agents
async def my_agent(job: agents.JobContext):
# my agent logic
pass
if __name__ == "__main__":
async def job_handler(job_request: agents.JobRequest):
await job_request.accept(my_agent)
worker = agents.Worker(job_handler)
agents.run_app(worker)Registering an agent with LiveKit’s worker service for agent orchestration
The same agent you develop locally, using a local instance of LiveKit server, can be deployed and scaled to thousands of servers using LiveKit Cloud without changing a single line of code. Our goal is to make stateful agents as easy to scale as web servers.
Like our other products and services, the Agents framework is based off real-world use cases and work we’ve done with developers already building multimodal AI applications.
One team deploys an agent in 911 dispatch centers around the United States. It assists human dispatchers by extracting context from speech, and detects firearms and license plates in streaming video. Another team is building an AI sports analyst that watches live games, tracks and surfaces player scores and stats, and can generate clips or replays on-the-fly.
A developer that owns call centers around the world is rebuilding their software stack from the ground up to use AI. An end-user can call in using LiveKit SIP and support requests are routed to the next available AI agent. If a call is escalated to a human supervisor, the agent will bring them into a session and patiently listen and learn from the ensuing conversation.
I just spoke with a founder building an AI-powered toy for children. And another is building a platform for LLM-driven NPCs in role-playing games. Even Justin Uberti, the creator of WebRTC, used LiveKit Agents to build a microsite for having fun, holiday-themed conversations with Santa and his friends.
A common thread linking several of these applications is the use of voice or video as native IO. Any phone or intercom-based system, such as digital assistants, food ordering, medical advice lines, or customer support centers, are a natural fit for an AI agent-based solution. Similarly, applications that rely on input from cameras, such as live video broadcasts, security and surveillance systems, autonomous vehicles, or wearable devices are also suitable candidates.
In the future though, we believe AI will be at the core of every application.
We’re excited for you to try LiveKit Agents and to support you as you build Software 2.0. Any feedback you have will be instrumental as we make improvements during this Developer Preview phase. You can reach us at hello@livekit.io or in the LiveKit community Slack. Happy hacking!
🤖