Introducing LiveKit Inference: A unified model interface for voice AI


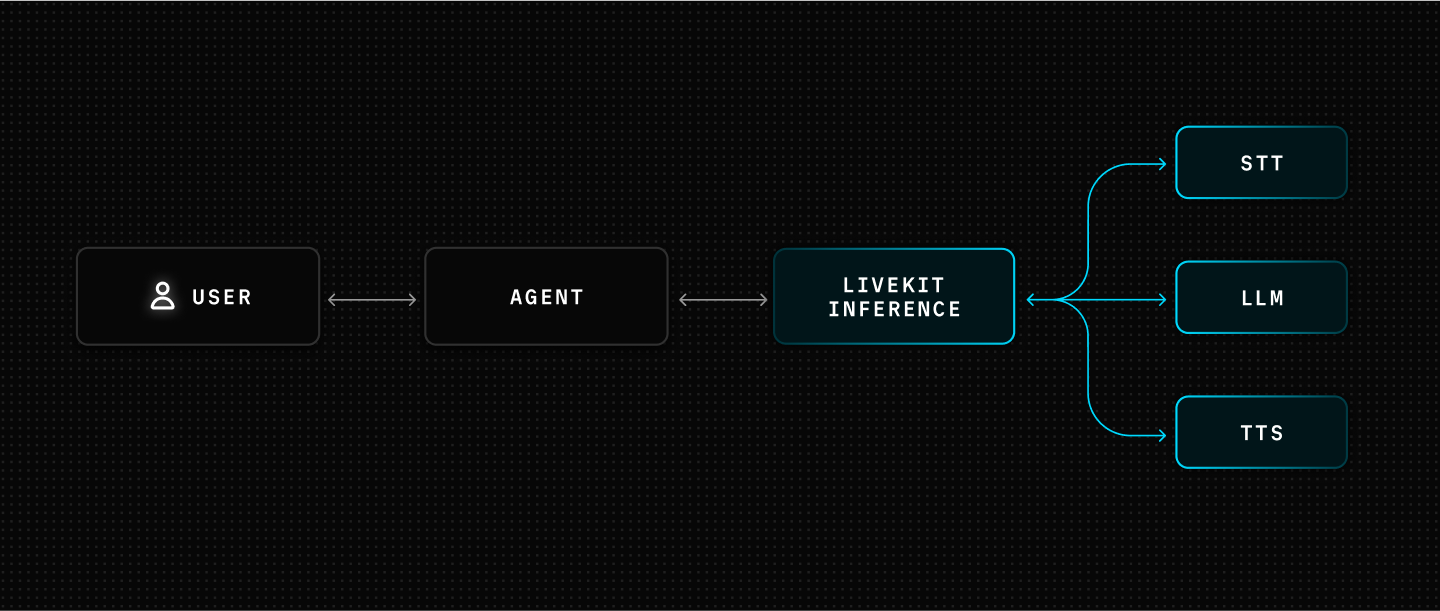
We’re excited to launch LiveKit Inference, a low-latency model gateway, purpose-built for voice AI. With just your LiveKit API key, you can use top-performing speech-to-text (STT), large language model (LLM), and text-to-speech (TTS) models. You no longer have to create and manage multiple provider accounts and integrations.
We've partnered with leading model providers to offer best-in-class performance across the voice agent stack. With a single LiveKit key, you can now access models from:
- STT: AssemblyAI, Cartesia, Deepgram
- LLM: OpenAI, Google DeepMind, Cerebras, Groq, Baseten
- TTS: Cartesia, ElevenLabs, Inworld, Rime
LiveKit Inference is available to all users today and every LiveKit Cloud plan includes free monthly usage credits.
A unified API for calling models
One of the first decisions you make when building a voice agent is choosing your model stack. Models vary in latency, reliability, speaking style, and language support, so it's worth trying a few to see which ones best match the needs of your use case. But testing different models isn't easy. Each provider requires separate API keys, billing setup, and integration work. On top of that, there’s no consistent API across STT and TTS, since each provider handles things differently.
LiveKit Inference simplifies this process. You can now access supported models through a consistent API, with no additional plugins, billing accounts, or setup required:
session = AgentSession(
stt="assemblyai/universal-streaming",
llm="openai/gpt-4.1-mini",
tts="cartesia/sonic-2:6f84f4b8-58a2-430c-8c79-688dad597532",
turn_detection=MultilingualModel()
)
Swapping another voice into your agent pipeline is as easy as changing the TTS string value - for example, tts="inworld/inworld-tts-1:ashley".
LiveKit is the obvious choice for anyone building voice agents at scale. AssemblyAI is thrilled to offer our leading Streaming STT models through LiveKit Inference.
-Dylan Fox, Founder and CEO
LiveKit has long set the standard for real-time developer infrastructure. We're excited to deepen our relationship with LiveKit as the primary Text to Speech provider for LiveKit Inference. Cartesia and LiveKit have a shared mission to define the foundational paradigms for AI.
-Karan Goel, Cofounder and CEO
Simplified concurrency management
As you move from development to production, concurrency limits become the next pain point. Most model providers throttle usage on developer accounts, but each one does it differently:
- STT concurrency (i.e., WebSocket connections)
- LLM limits on tokens per minute
- TTS concurrent generations
These limits become hard to track, especially as your voice agent starts to scale. You need visibility into your usage of a specific provider, and capacity planning is mostly guesswork.
LiveKit Inference gives you a unified view of all concurrency limits in your LiveKit Cloud dashboard. Limits are applied by model type, not by provider, meaning you can, for example, switch between LLM model families like OpenAI and Gemini without having to renegotiate quotas or worry about compatibility.
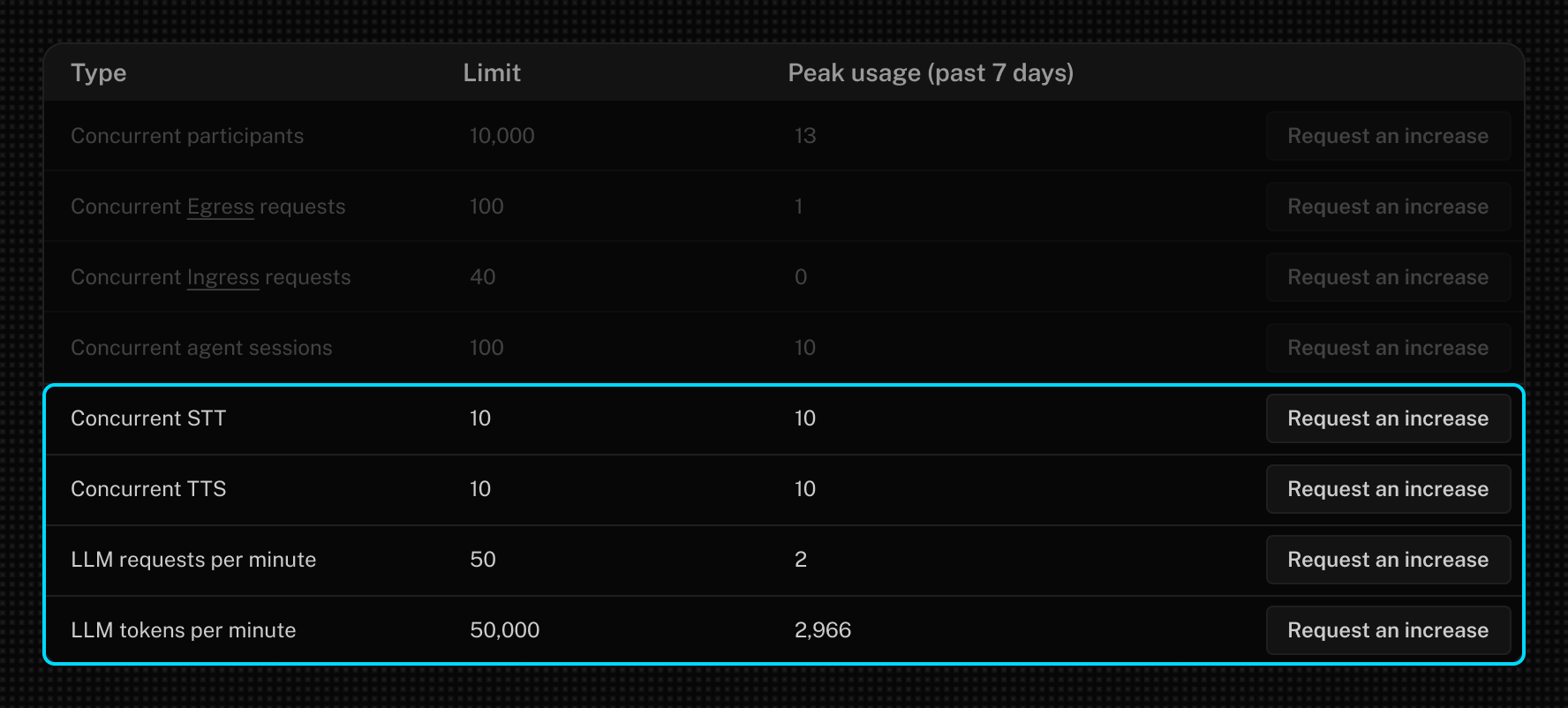
In addition to rate limit management, LiveKit Inference consolidates billing across providers. Models called via LiveKit Inference are billed based on the PAYG prices for each provider.
Optimizing for latency and reliability
End-to-end latency is critically important for voice agents. In a text-based app, making a user wait a few extra seconds for a response is generally acceptable (or even desired with reasoning models). But when talking to AI, delays make conversations feel awkward or unnatural.
Model performance is the biggest contributor to overall latency in a voice agent. Once you roll out your agent to real users, it’s common to see unexpected spikes in latency. Many providers queue requests to their public inference endpoints during periods of high demand. These delays or failures can disrupt the conversation and make your agent feel unresponsive, which significantly impacts the user experience:
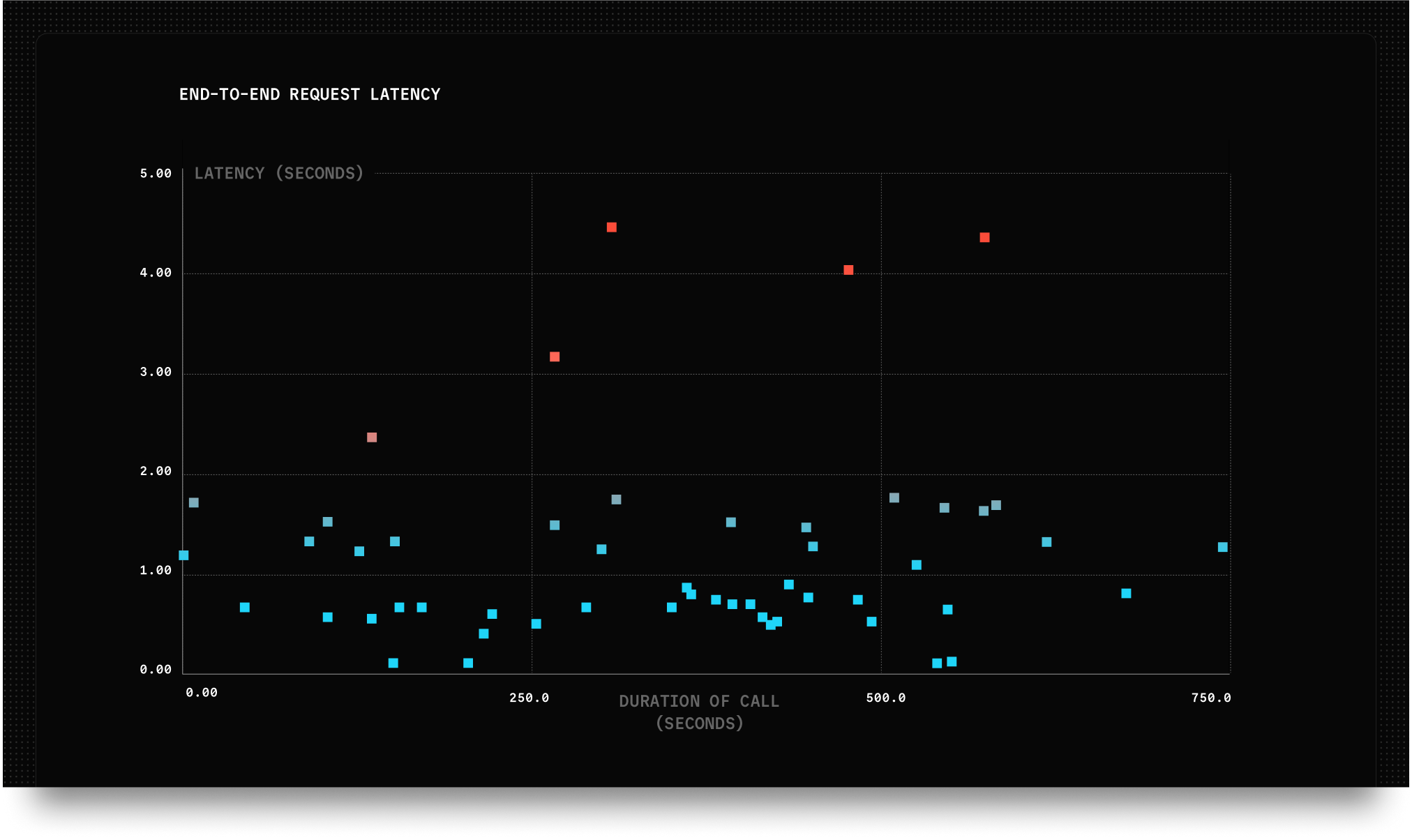
LiveKit Inference reduces latency and improves reliability in a few important ways:
Global co-location
LiveKit's cloud infrastructure is deployed across a global network of data centers. When you deploy your agent to LiveKit Cloud, it runs in the same data center as our inference service. API calls between your agent and models travel across our private network backbone, avoiding congestion on the public internet.
Provisioned capacity
We work directly with model providers to secure provisioned inference capacity. This gives us dedicated access to their models and allows us to bypass public inference endpoints, which are more likely to experience congestion during peak demand.
Dynamic routing (coming soon)
Leveraging the routing infrastructure we built for streaming voice and video data between data centers with low latency, we’re building a routing system that monitors real-time inference latency and availability across regions and providers. With this information, we can intelligently reroute requests to alternative providers or data centers when we detect slowdowns or outages, giving your agents predictable latency and uptime.
LiveKit Inference is available today and can be used across both Python and Node Agents SDKs. A great place to start is our voice AI quickstart guide and our agent examples, which have been updated to use it by default.
We built LiveKit Inference to make it easier for developers to focus on building voice-driven AI products for their customers while we take care of the undifferentiated infrastructure work. Give it a try and let us know what you think!