Improved end-of-turn model cuts Voice AI interruptions 39%



We're excited to release a new iteration of our transformer-based end-of-turn detection model, v0.4.1-intl, which pushes the boundaries of accuracy and responsiveness. This update focuses on detecting speech completion for structured inputs and better generalization across languages.
The latest MultilingualModel has been deployed to agents running on LiveKit Cloud, and is available in Agents Python 1.3.0 and Agents JS 1.0.19.
The challenge of end-of-turn detection
End-of-turn detection is one of the most challenging problems in voice AI. Humans perform it naturally in conversations by relying on three primary cues:
- Semantic content: The meaning of words that are spoken
- Context: The broader dialogue history, including what the other party just said
- Prosody: Delivery elements like tone, pauses, and rhythm
Overlooking any of these cues can result in interruptions or awkward silences.
For voice AI agents, this requires real-time processing of live audio streams, followed by analysis of the resulting audio or text. To achieve human-level performance, models must integrate content, context, and delivery cues.
At LiveKit, our transformer-based model uses an LLM backbone to effectively combine content and context. This foundation enables the improvements in v0.4.1-intl.
Key improvements: reduced interruptions and multilingual voice AI gains
Benchmarks demonstrate a 39.23% relative reduction in false-positive interruptions with v0.4.1-intl compared to v0.3.0-intl, with no increase in response latency. These gains hold across all tested languages, as shown below (error rate is defined as the false positive rate at a fixed true positive rate of 99.3%).
| Language | v0.3.0 error rate | v0.4.1 error rate | Relative Improvement |
|---|---|---|---|
| Chinese | 18.70% | 13.40% | 28.34% |
| Dutch | 26.10% | 11.90% | 54.33% |
| English | 16.60% | 13.00% | 21.69% |
| French | 16.80% | 11.10% | 33.93% |
| German | 23.40% | 12.20% | 47.86% |
| Hindi | 5.40% | 3.70% | 31.48% |
| Indonesian | 17.00% | 10.60% | 37.65% |
| Italian | 20.10% | 14.90% | 25.87% |
| Japanese | 19.70% | 11.20% | 43.15% |
| Korean | 7.90% | 5.50% | 30.38% |
| Portuguese | 23.30% | 12.60% | 45.97% |
| Russian | 19.50% | 12.00% | 38.46% |
| Spanish | 21.50% | 14.00% | 33.88% |
| Turkish | 25.40% | 12.70% | 50.0% |
| All | 18.66% | 11.34% | 39.23% |
The overall 39.23% relative improvement reflects refinements in training strategy, dataset composition, and preprocessing. In particular, these changes enhance handling of structured inputs, such as emails, addresses, phone numbers, and credit card details, by minimizing premature interruptions.
With this release, we will be deprecating our EnglishModel . The latest MultilingualModel not only matches but in most cases exceeds the performance of the legacy English model, while delivering consistent accuracy across all supported languages. Going forward, we recommend using the multilingual model for both English and non‑English use cases, so your voice agents benefit from a single, best-performing model regardless of where your users are.
Handling structured data
Consider a common voice AI scenario, such as collecting information from a user. The agent prompts: "What's your phone number?" The user recites digits, possibly with hesitations or corrections. Unlike natural speech with clear grammatical endings or prosodic signals, structured data lacks obvious breaks—intonation remains flat, with no rise or fall to indicate completion.
Without strong context awareness, models risk incomplete captures, forcing users to repeat information. v0.4.1-intl addresses this by inferring expected formats from the agent's prompt:
- A US phone number typically consists of 10 digits
- An email follows a pattern like
user at domain dot com - Addresses typically include street address, city, state, and zip code
The LLM backbone enables the model to wait for format completion, unlike smaller audio-only models that lack semantic depth and struggle with these nuances.
The comparison below illustrates this for a spoken phone number utterance. v0.3.0-intl detects the end prematurely after each digit while v0.4.1-intl holds until the full sequence.
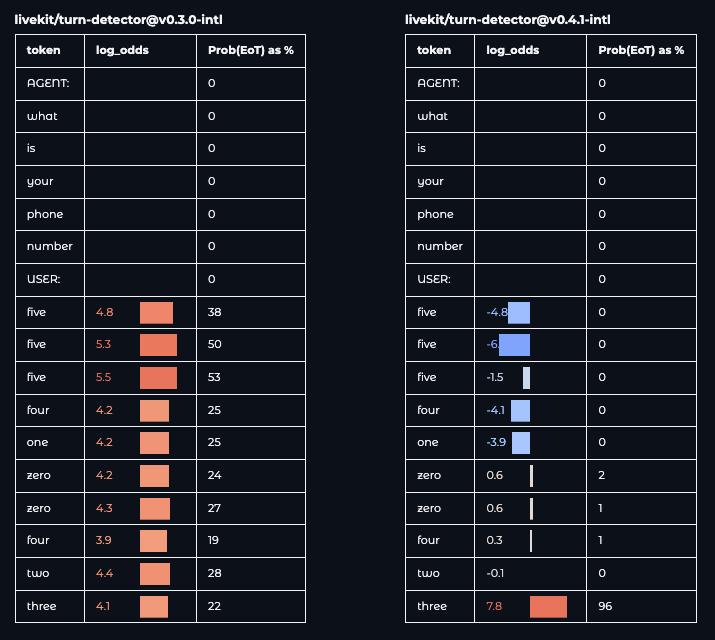
To see the difference for yourself, try our visualization tool on Hugging Face.
These capabilities stem from an expanded training dataset, incorporating real call center transcripts and synthetic dialogues emphasizing structured data like addresses, emails, phone numbers, and credit cards.
Adapting to real-world variability
Since the model processes text output from speech-to-text (STT) systems, inconsistencies across providers can impact performance. One STT engine might transcribe "forty two" as words, while another outputs "42" as numerals. Training on one style and deploying with another leads to degraded accuracy.
To handle this, we varied the training data across common STT output formats. This ensures consistent predictions in diverse environments without adding runtime overhead.
Building on this robustness, the model shows strong multilingual generalization. Although structured data enhancements were added only to the English training set, performance improved in other languages—for example, phone number detection in Spanish or French with minimal accuracy drops. This transfer arises from the Qwen2.5 base model, pre-trained on multilingual corpora, which encodes knowledge of global formats (e.g., international addresses) and reduces the need for language-specific datasets.
Achieving efficiency: model distillation
We selected Qwen2.5-0.5B-Instruct as the base model for its strong performance on turn detection while supporting low-latency CPU inference.
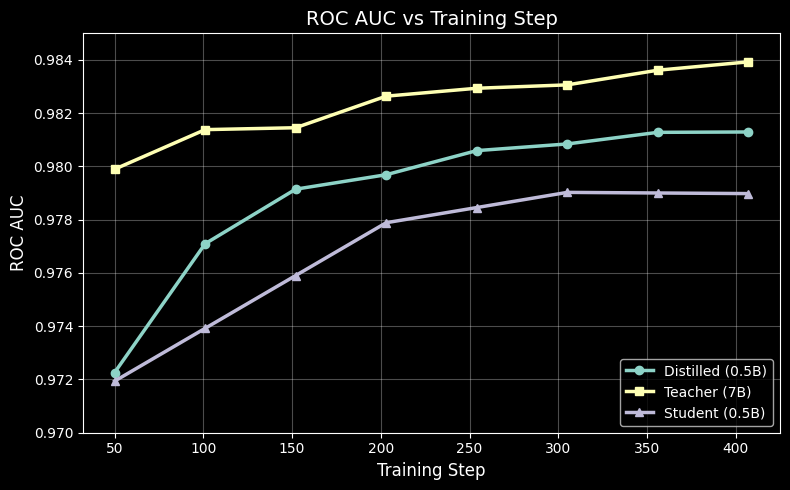
Larger models, however, provide better cross-lingual generalization. To balance this, we trained a 7-billion-parameter Qwen2.5-7B-Instruct as a teacher model and distilled its knowledge into the 0.5B student. The resulting model delivers higher multilingual accuracy with the efficiency of the smaller size.
The figure below tracks evaluation AUC during training. The distilled model (orange) outperforms the baseline 0.5B (green) and approaches the teacher's performance (blue) after approximately 1,500 steps.
Observability integration
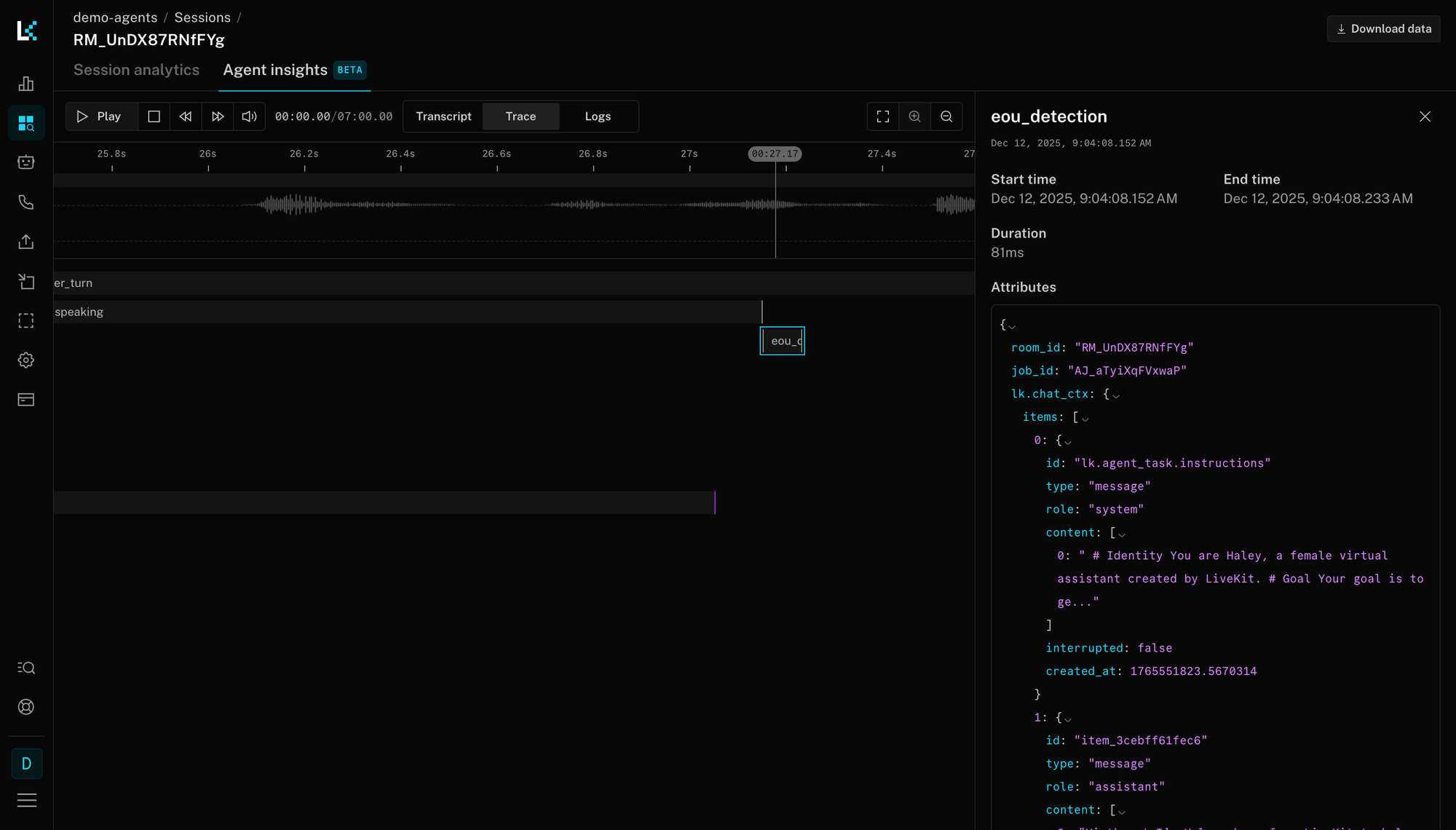
LiveKit Agents now include built-in observability for the end-of-turn model.
When you enable Agent Observability, every turn detection decision is logged with the exact input the model saw.
In the session replay view, click on eou_detection trace and see the full context that produced the prediction. This makes debugging production issues straightforward.
Looking ahead
Our current model relies on transcribed text and does not yet incorporate raw audio features like pauses or emphasis. Future iterations will integrate these through multimodal architectures, fusing prosody directly into predictions for more precise detection.
As we continue refining these tools, our goal is to make voice AI interactions more natural and human-like. This ongoing work will power the next generation of conversational AI, enabling more intuitive and efficient experiences for both developers and users.
Ready to build with the latest turn detection model? Get started with the Voice AI Quickstart or sign up for LiveKit Cloud.